

Vintern-1B-v3.5 ❄️
We introduce Vintern-1B-v3.5, the latest version in the Vintern series, offering significant improvements over v2 across all evaluation benchmarks. This model has been fine-tuned from InternVL2.5-1B, which already good in Vietnamese 🇻🇳 tasks because it used Viet-ShareGPT-4o-Text-VQA data during its fine-tuning process by the InternVL 2.5 [1] team.

To further enhance its performance in Vietnamese while maintaining good capabilities on existing English datasets, Vintern-1B-v3.5 has been fine-tuned using a vast amount of Vietnamese-specific data. This results in a model that is exceptionally powerful in text recognition, OCR, and understanding Vietnam-specific documents.
Highlights 🌟
Top Quality for Vietnamese Texts Vintern-1B-v3.5 is one of the best models in its class (1B parameters) for understanding and processing Vietnamese documents.
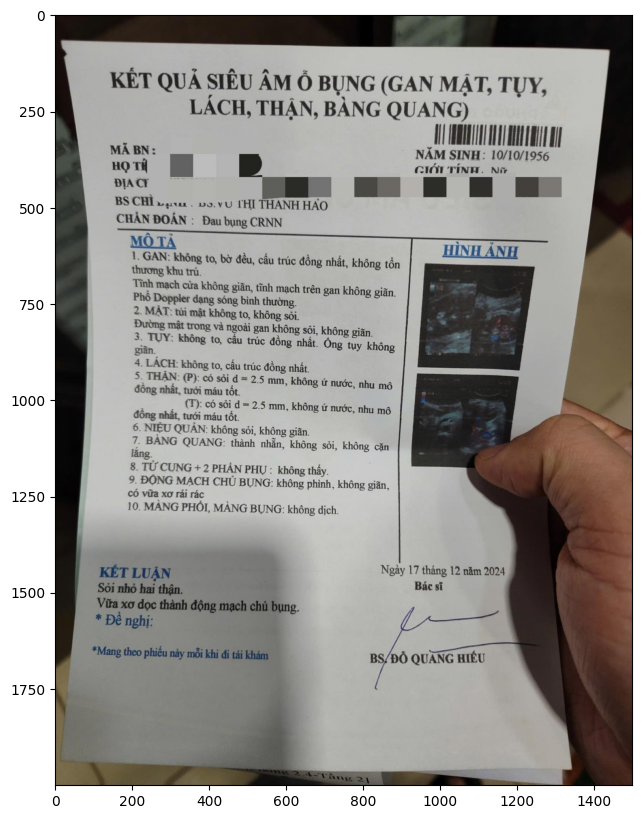
Better Extraction and Understanding The model is great at handling invoices, legal texts, handwriting, and tables.
Improved Prompt Understanding It can understand more complex prompts compared to v2, making it easier to work with.
Runs on Affordable Hardware You can run the model on Google Colab with a T4 GPU, making it easy to use without expensive devices.
Easy to Fine-tune The model can be customized for specific tasks with minimal effort.
Benchmarks 📈
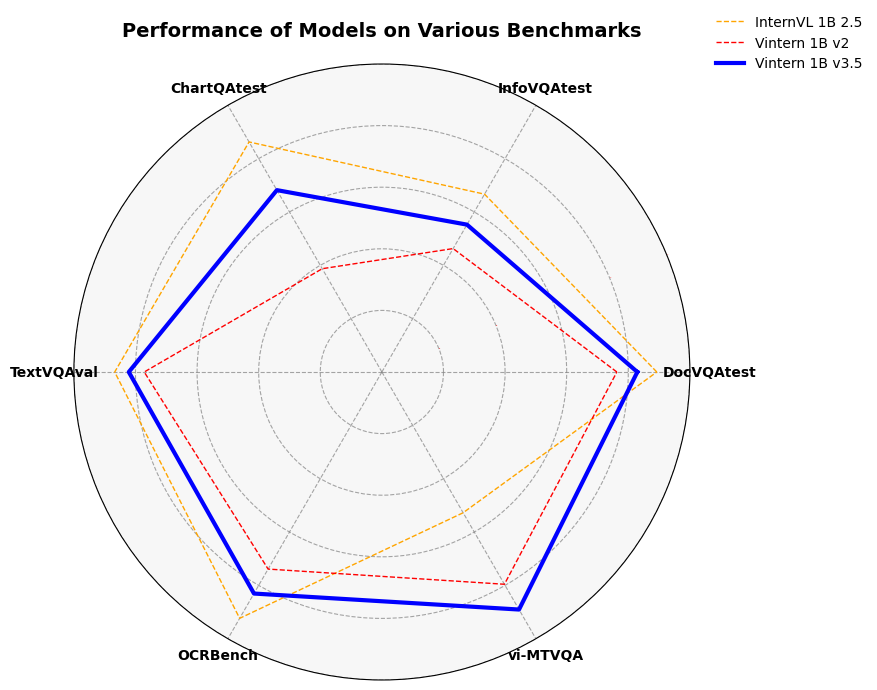
| Benchmark | InternVL2_5 1B | Vintern-1B-v2 | Vintern-1B-v3.5 |
|---|---|---|---|
| vi-MTVQA | 24.8 | 37.4 | 41.9 |
| DocVQAtest | 84.8 | 72.5 | 78.8 |
| InfoVQAtest | 56.0 | 38.9 | 46.4 |
| TextVQAval | 72.0 | 64.0 | 68.2 |
| ChartQAtest | 75.9 | 34.1 | 60.0 |
| OCRBench | 785 | 628 | 706 |
Examples
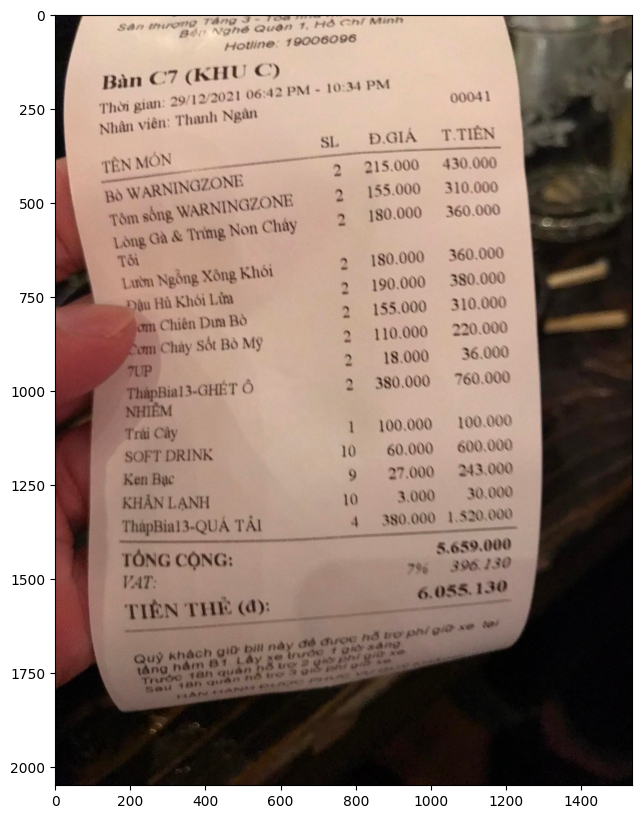
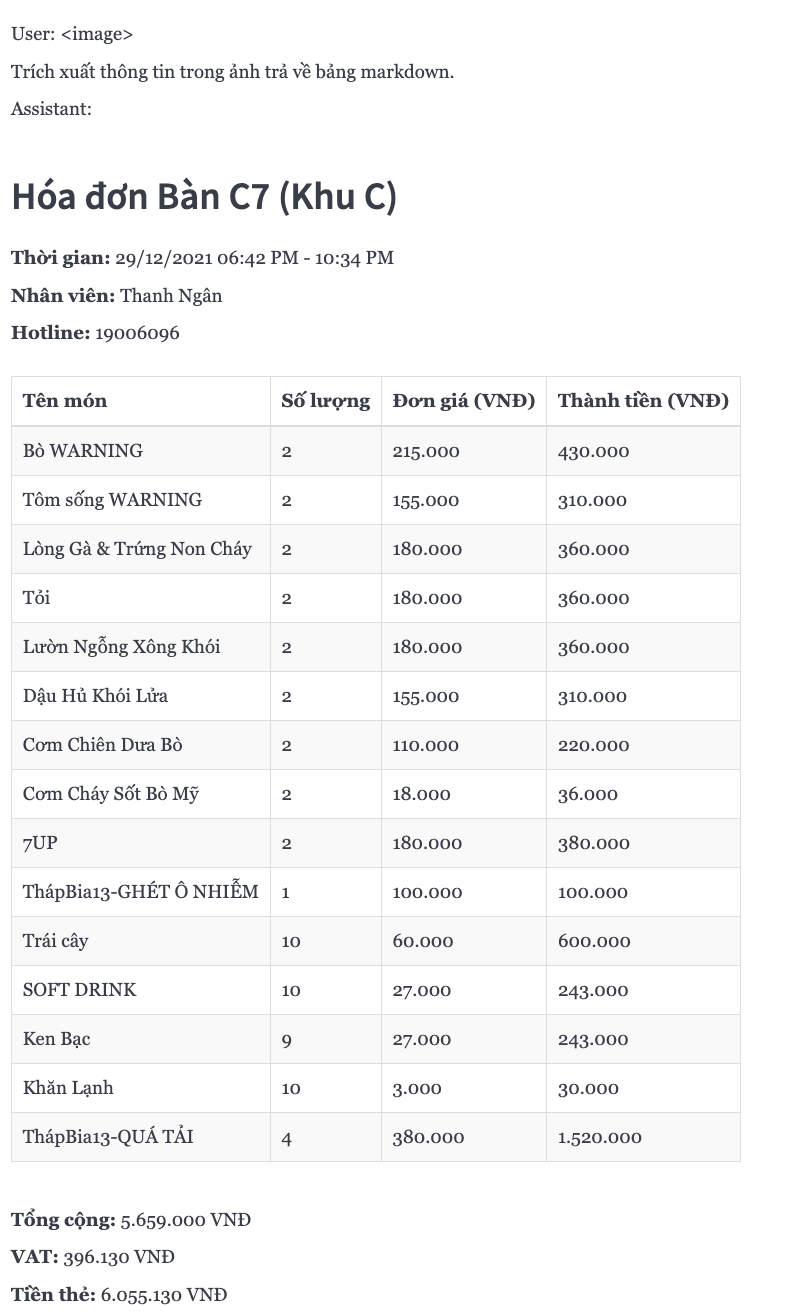





Quickstart
Here provides a code snippet to show you how to load the tokenizer and model and how to generate contents.
To run inference using the model, follow the steps outlined in our Colab inference notebook
![]()
import numpy as np
import torch
import torchvision.transforms as T
# from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
model = AutoModel.from_pretrained(
"5CD-AI/Vintern-1B-v3_5",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
use_flash_attn=False,
).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained("5CD-AI/Vintern-1B-v3_5", trust_remote_code=True, use_fast=False)
test_image = 'test-image.jpg'
pixel_values = load_image(test_image, max_num=6).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens= 1024, do_sample=False, num_beams = 3, repetition_penalty=2.5)
question = '<image>\nTrích xuất thông tin chính trong ảnh và trả về dạng markdown.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
#question = "Câu hỏi khác ......"
#response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
#print(f'User: {question}\nAssistant: {response}')
Citation
@misc{doan2024vintern1befficientmultimodallarge,
title={Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese},
author={Khang T. Doan and Bao G. Huynh and Dung T. Hoang and Thuc D. Pham and Nhat H. Pham and Quan T. M. Nguyen and Bang Q. Vo and Suong N. Hoang},
year={2024},
eprint={2408.12480},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2408.12480},
}
Reference
[1] Z. Chen et al., ‘Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling’, arXiv preprint arXiv:2412. 05271, 2024.
- Downloads last month
- 224
Model tree for 5CD-AI/Vintern-1B-v3_5
Base model
OpenGVLab/InternVL2_5-1B