
GRAG-PHI-4B (German Retrieval Augmented Generation)
Collection
Here you can find all the final checkpoints & datasets from training Phi-3.5-mini-128k Model from Microsoft on the GRAG Datasets.
•
10 items
•
Updated
GRAG (German Retrieval Augmented Generation) models are designed for the German-speaking market, enabling innovation and AI solutions to drive German research collaboration in business-focused Generative AI by 2025
The core models released in this batch are the following:
| Size | Training Tokens |
|---|---|
| GRAG-PHI-CPT | 507.47 million |
| GRAG-PHI-SFT | 2.03 billion |
| GRAG-PHI-ORPO | 2.0577 billion |
This model was merged using the SLERP merge method.
The following models were included in the merge:
The following YAML configuration was used to produce this model:
slices:
- sources:
- model: avemio/GRAG-PHI-3.5-MINI-4B-SFT-HESSIAN-AI
layer_range: [0, 32]
- model: avemio/GRAG-PHI-3.5-MINI-4B-ORPO-HESSIAN-AI
layer_range: [0, 32]
merge_method: slerp
base_model: avemio/GRAG-PHI-3.5-MINI-4B-ORPO-HESSIAN-AI
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
Quickly get inference running with the following required installation: Now, proceed as usual with HuggingFace:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "avemio/GRAG-PHI-3.5-MINI-4B-MERGED-HESSIAN-AI"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
im_end_token_id = tokenizer.convert_tokens_to_ids('<|im_end|>')
im_start_token_id = tokenizer.convert_tokens_to_ids('<|im_start|>')
messages = [
{"role": "system", "content": "Folge den Anweisungen des Benutzers. Bevor du deine finale Antwort gibst, schildere deine Überlegungen zur Lösung des Problems."},
{"role": "user", "content": "Ferdinand steht vor der Herausforderung, eine faire Besuchsregelung für seine drei Kinder zu finden, die den Bedürfnissen jedes einzelnen Kindes gerecht wird. Jedes Kind hat unterschiedliche Vorlieben und Bedürfnisse, die in den Besuchsplan integriert werden müssen. Er muss sicherstellen, dass die Regelung sowohl den Interessen der Kinder als auch den rechtlichen Vorgaben entspricht. Ferdinand hat eine Woche Zeit, um einen Vorschlag zu erarbeiten, den er mit seinem Anwalt besprechen kann."}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_length=2024,
temperature=0.01,
do_sample=False,
#bos_token_id=im_start_token_id,
eos_token_id=im_end_token_id,
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
num_return_sequences=1,
top_k=40,
top_p=0.95,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
We are providing a comprehensive Google Colab notebook to guide users through the process of fine-tuning our model, complete with detailed instructions, essential dependencies, and configurable settings. Colab-Notebook.
The evaluation was performed using seven subsets, focusing on extraction recall, question answering (QA) with multiple references, and time difference reasoning. Relevant context and summarization were treated as distinct subsets, each playing a crucial role in the evaluation process. For relevant context, the model's ability to identify and extract pertinent information from the source material was assessed. In contrast, the summarization subset evaluated the model's capability to generate concise and accurate summaries based on the relevant context.
Four evaluation metrics were employed across all subsets: language quality, overall correctness, instruction following, and an overall score.
| Metric | Vanilla-Phi-3.5-Mini-4B | GRAG-PHI-SFT | GRAG-PHI-ORPO | GRAG-PHI-MERGED | GPT-3.5-TURBO |
|---|---|---|---|---|---|
| Average Language Quality | 75.11 | 78.88 | 78.13 | 85.41 | 91.86 |
| OVERALL SCORES (weighted): | |||||
| extraction_recall | 18.0 | 37.5 | 32.0 | 61.8 | 87.2 |
| qa_multiple_references | 65.8 | 70.6 | 74.8 | 84.8 | 77.2 |
| qa_without_time_difference | 71.2 | 88.0 | 87.3 | 88.0 | 83.1 |
| qa_with_time_difference | 64.6 | 89.3 | 86.9 | 89.1 | 83.2 |
| relevant_context | 72.3 | 72.8 | 69.1 | 84.4 | 89.5 |
| summarizations | 74.6 | 83.2 | 81.1 | 84.9 | 86.9 |
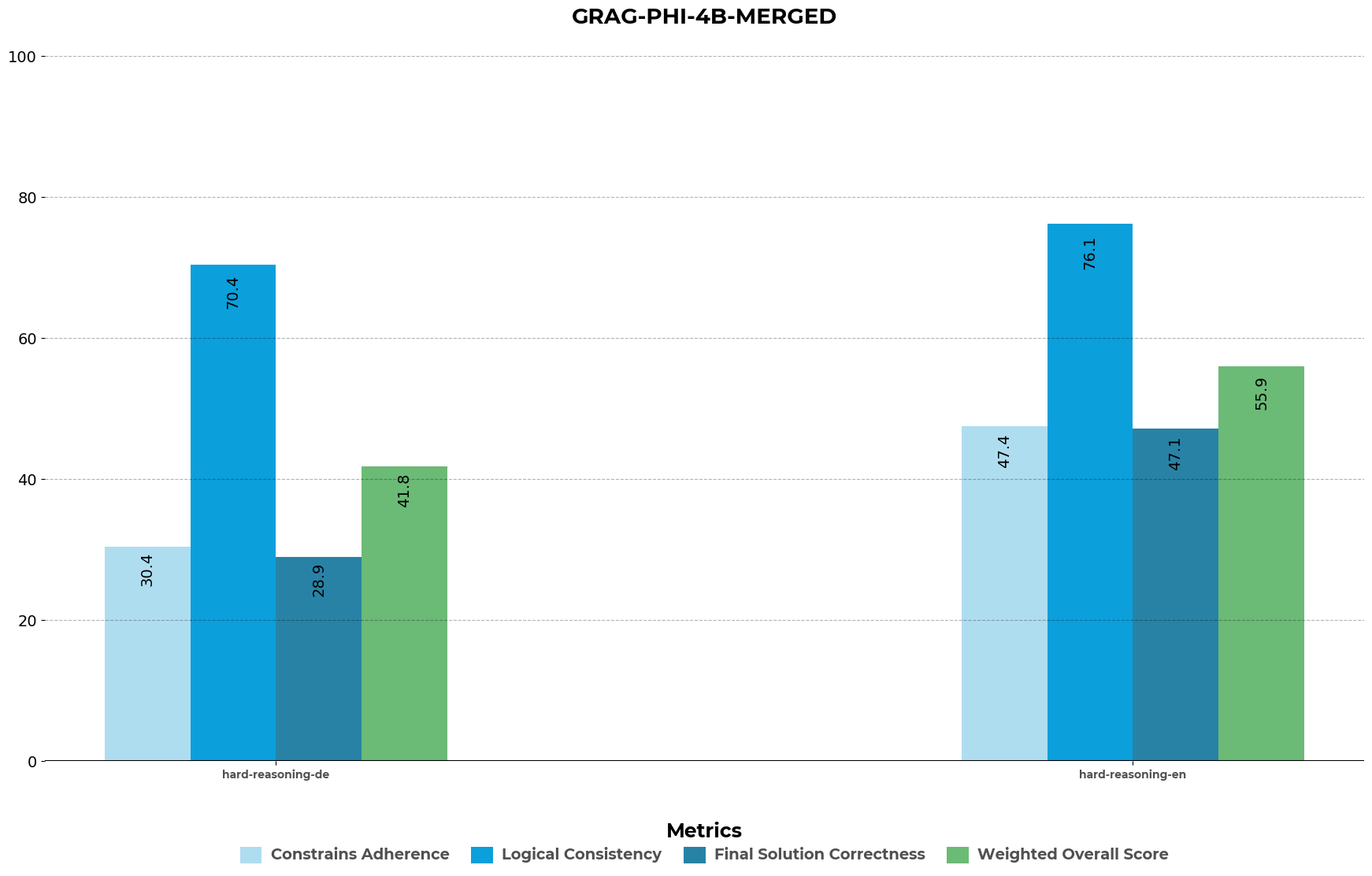
| Metric | Vanila-PHI-4B-Instruct | GRAG-PHI-Merged | GPT-3.5-TURBO | GPT-4o | GPT-4o-mini |
|---|---|---|---|---|---|
| OVERALL SCORES (weighted): | |||||
| hard_reasoning_de | 42.8 | 41.8 | 37.9 | 62.9 | 58.4 |
| hard_reasoning_en | 50.8 | 55.9 | 48.3 | 61.7 | 62.9 |
| Parameter | GRAG-PHI-MERGED |
|---|---|
| d_model | 3072 |
| num heads | 32 |
| num layers | 32 |
| MLP ratio | 2.66 |
| LayerNorm type | RMSNorm |
| pos embeddings | RoPE |
| attention variant | Standard Multi-Head Self Attention with sliding-window of 2047 |
| biases | none |
| block type | sequential |
| activation | SiLU |
| sequence length | 131072 |
| weight tying | bfloat16 |
Like any base language model or fine-tuned model without safety filtering, it is relatively easy for a user to prompt these models to generate harmful and generally sensitive content. Such content can also be produced unintentionally, especially in the case of bias, so we recommend users consider the risks of applications of this technology.
Otherwise, many facts from GRAG-PHI-MERGED or any LLM will often not be true, so they should be checked.
For errors in this model card, please contact ([email protected]).