
Dataset Card for Dataset Name

Arxiv: Arxiv | Website: Biomedica | Training instructions: OpenCLIP | Tutorial: Google Colab
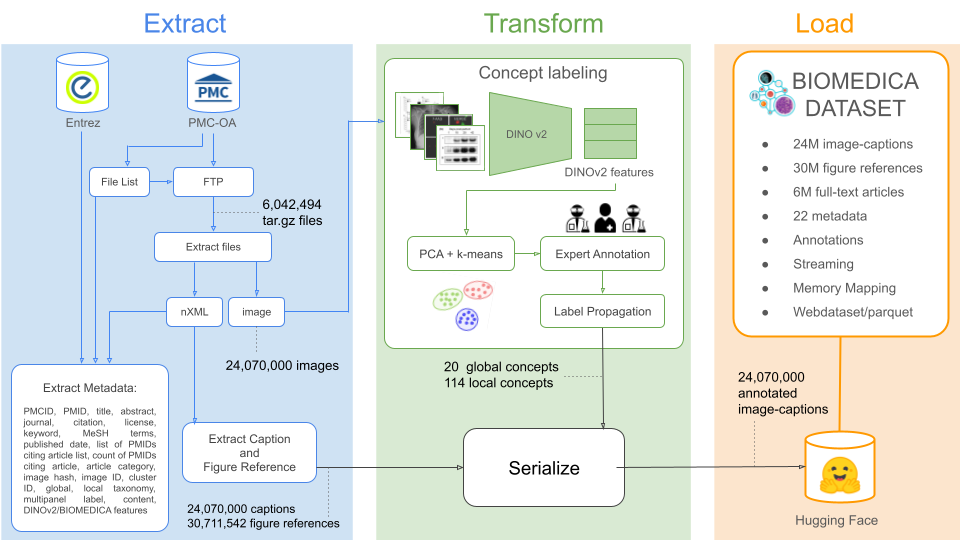
BIOMEDICA Dataset is a large-scale, deep-learning-ready biomedical dataset containing over 24M imagecaption pairs and 30M image-references from 6M unique open-source articles. Each data point is highly annotated with over 27 unique metadata fields, including article level information (e.g., license, publication title, date, PMID, keywords, MeSH terms) and coarse-grained image metadata (e.g., primary and secondary content labels and panel type) assigned via an unsupervised algorithm and human curation by a group of seven experts (clinicians and scientists).
BIOMEDIC\biomedica_webdataset is a serialized version of the BIOMEDICA dataset optimized for model development and formatted as a WebDataset for high-throughput streaming. This format provides 3x–10x higher I/O rates compared to random access memory.
Dataset Details
Dataset Description
- Curated by: Min Woo Sun and Alejandro Lozano
- Language(s) (NLP): English
- License: Varies depending on the dataset subset.
Dataset Sources [optional]
- Downloads last month
- 9